
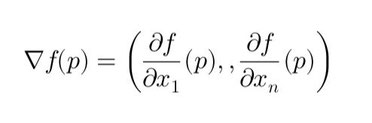
In mathematics, the gradient of a function \( f \) at a point \( p \) in an open set \( U \subset \mathbb{R}^n \) is the vector:
\[ \nabla f(p) = \left( \frac{\partial f}{\partial x_1}(p), \dots, \frac{\partial f}{\partial x_n}(p) \right) \]
If \( f(x, y, z) = 0 \) defines a surface \( S \), at a regular point \( P \), the gradient is normal (orthogonal) to the tangent plane of \( S \).
The gradient points in the direction of the steepest ascent, meaning that for any unit vector \( u \), the function increases most rapidly in the direction of \( \nabla f(p) \).
At a local extremum \( x^* \), \( \nabla f(x^*) = 0 \), meaning no further improvement is possible.
With a constraint \( g(x) = 0 \), optimality is given by \( \nabla f(x^*) = \lambda \nabla g(x^*) \), meaning \( \nabla f \) is orthogonal to the constraint surface.
This ensures gradient descent converges to an optimal solution.
The symbol \( \nabla \) was introduced by W. Hamilton in 1847. Tait renamed it “nabla” in 1870, inspired by the shape of a Hebrew harp.
Purpose of Calibration
In finance, calibration ensures that a model accurately fits observed market data. Gradient descent helps find the optimal parameters by reducing pricing errors iteratively.
Hull-White Model
The Hull-White model describes short-term interest rates:
\[ dr_t = \kappa (\theta(t) - r_t) dt + \sigma dW_t \]
where:
- \( r_t \) = short-term interest rate at time \( t \)
- \( \kappa \) = mean-reversion speed (how fast \( r_t \) returns to \( \theta \))
- \( \theta(t) \) = time-dependent drift term
- \( \sigma \) = volatility of \( r_t \) (to be calibrated)
- \( W_t \) = Brownian motion (randomness)
Calibrating \( \sigma \) with Gradient Descent
We calibrate \( \sigma \) by minimizing the squared error between model and market bond prices.
Step 1: Define the Loss Function
\[ L(\sigma) = \sum (P_{\text{model},i}(\sigma) - P_{\text{market},i})^2 \]
where \( P_{\text{model},i}(\sigma) \) is the model bond price and \( P_{\text{market},i} \) is the observed market price.
Step 2: Compute the Gradient
\[ \frac{dL}{d\sigma} = \sum 2 (P_{\text{model},i}(\sigma) - P_{\text{market},i}) \cdot \frac{\partial P_{\text{model},i}}{\partial \sigma} \]
where \( \frac{\partial P_{\text{model},i}}{\partial \sigma} \) is the bond price sensitivity to \( \sigma \).
Step 3: Update \( \sigma \) Using Gradient Descent
\[ \sigma_{\text{new}} = \sigma_{\text{old}} - \alpha \frac{dL}{d\sigma} \]
where \( \alpha \) is the learning rate controlling step size.
Step 4: Iterate Until Convergence
Repeat until the change in \( \sigma \) is small or \( L(\sigma) \) stops decreasing.
Assume:
- Market bond prices: \( P_{\text{market}} = [0.98, 0.95, 0.90] \)
- Initial model bond prices (\( \sigma_0 = 0.02 \)): \( P_{\text{model}} = [0.97, 0.94, 0.89] \)
- Learning rate \( \alpha = 0.01 \)
Iteration 1: Compute the Gradient
\[ \frac{dL}{d\sigma} = 2 [(0.97 - 0.98) \cdot (-0.1) + (0.94 - 0.95) \cdot (-0.12) + (0.89 - 0.90) \cdot (-0.15)] \]
\[ = 2 (0.001 + 0.0012 + 0.0015) = 0.0074 \]
Iteration 1: Update \( \sigma \)
\[ \sigma_{\text{new}} = 0.02 - (0.01 \times 0.0074) = 0.01993 \]
Repeating this process, \( \sigma \) converges to an optimal value, reducing pricing errors.
🎓 Recommended Training: The Fundamentals of Quantitative Finance
Discover the essential concepts of quantitative finance, explore applied mathematical models, and learn how to use them for risk management and asset valuation.
Explore the Training
Écrire commentaire