
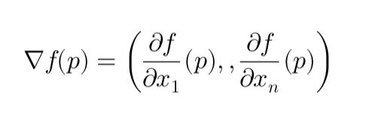
En mathématiques, le gradient d'une fonction \( f \) en un point \( p \) dans un ensemble ouvert \( U \subset \mathbb{R}^n \) est le vecteur :
\[ \nabla f(p) = \left( \frac{\partial f}{\partial x_1}(p), \dots, \frac{\partial f}{\partial x_n}(p) \right) \]
Si \( f(x, y, z) = 0 \) définit une surface \( S \), en un point régulier \( P \), le gradient est normal (orthogonal) au plan tangent de \( S \).
Le gradient pointe dans la direction de la montée la plus rapide, ce qui signifie que pour tout vecteur unitaire \( u \), la fonction augmente le plus rapidement dans la direction de \( \nabla f(p) \).
En un extremum local \( x^* \), \( \nabla f(x^*) = 0 \), ce qui signifie qu'aucune amélioration supplémentaire n'est possible.
Avec une contrainte \( g(x) = 0 \), l'optimalité est donnée par \( \nabla f(x^*) = \lambda \nabla g(x^*) \), ce qui signifie que \( \nabla f \) est orthogonal à la surface de contrainte.
Cela garantit que la descente de gradient converge vers une solution optimale.
Le symbole \( \nabla \) a été introduit par W. Hamilton en 1847. Tait l'a renommé « nabla » en 1870, inspiré par la forme d'une harpe hébraïque.
Objectif de la Calibration
En finance, la calibration garantit qu'un modèle s'ajuste précisément aux données de marché observées. La descente de gradient permet de trouver les paramètres optimaux en réduisant progressivement les erreurs de tarification.
Modèle de Hull-White
Le modèle de Hull-White décrit les taux d'intérêt à court terme :
\[ dr_t = \kappa (\theta(t) - r_t) dt + \sigma dW_t \]
où :
- \( r_t \) = taux d'intérêt à court terme à l'instant \( t \)
- \( \kappa \) = vitesse de retour à la moyenne (rapidité avec laquelle \( r_t \) revient vers \( \theta \))
- \( \theta(t) \) = terme de dérive dépendant du temps
- \( \sigma \) = volatilité de \( r_t \) (à calibrer)
- \( W_t \) = mouvement brownien (aléatoire)
Calibration de \( \sigma \) avec la Descente de Gradient
Nous calibrons \( \sigma \) en minimisant l'erreur quadratique entre les prix des obligations du modèle et ceux du marché.
Étape 1 : Définir la Fonction de Perte
\[ L(\sigma) = \sum (P_{\text{modèle},i}(\sigma) - P_{\text{marché},i})^2 \]
où \( P_{\text{modèle},i}(\sigma) \) est le prix des obligations du modèle et \( P_{\text{marché},i} \) est le prix observé sur le marché.
Étape 2 : Calculer le Gradient
\[ \frac{dL}{d\sigma} = \sum 2 (P_{\text{modèle},i}(\sigma) - P_{\text{marché},i}) \cdot \frac{\partial P_{\text{modèle},i}}{\partial \sigma} \]
où \( \frac{\partial P_{\text{modèle},i}}{\partial \sigma} \) est la sensibilité du prix de l'obligation à \( \sigma \).
Étape 3 : Mettre à Jour \( \sigma \) avec la Descente de Gradient
\[ \sigma_{\text{nouveau}} = \sigma_{\text{ancien}} - \alpha \frac{dL}{d\sigma} \]
où \( \alpha \) est le taux d'apprentissage contrôlant la taille du pas.
Étape 4 : Itérer Jusqu'à la Convergence
Répéter jusqu'à ce que la variation de \( \sigma \) soit négligeable ou que \( L(\sigma) \) cesse de diminuer.
Hypothèses :
- Prix des obligations de marché : \( P_{\text{marché}} = [0.98, 0.95, 0.90] \)
- Prix initiaux du modèle (\( \sigma_0 = 0.02 \)) : \( P_{\text{modèle}} = [0.97, 0.94, 0.89] \)
- Taux d'apprentissage \( \alpha = 0.01 \)
Itération 1 : Calcul du Gradient
\[ \frac{dL}{d\sigma} = 2 [(0.97 - 0.98) \cdot (-0.1) + (0.94 - 0.95) \cdot (-0.12) + (0.89 - 0.90) \cdot (-0.15)] \]
\[ = 2 (0.001 + 0.0012 + 0.0015) = 0.0074 \]
Itération 1 : Mise à Jour de \( \sigma \)
\[ \sigma_{\text{nouveau}} = 0.02 - (0.01 \times 0.0074) = 0.01993 \]
En répétant ce processus, \( \sigma \) converge vers une valeur optimale, réduisant les erreurs de tarification.
🎓 Formation recommandée : Les fondamentaux de la Finance Quantitative
Découvrez les concepts essentiels de la finance quantitative, explorez les modèles mathématiques appliqués et apprenez à les utiliser pour la gestion des risques et la valorisation des actifs.
Découvrir la formation
Écrire commentaire