
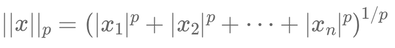
The concept of a norm, taught as early as high school, is a fundamental idea in mathematics. It measures the "size" or "length" of a vector, which belongs to a vector space¹. In quantitative
finance, this concept is used to quantify risks, measure distances between portfolios, or evaluate deviations in scenarios. However, some mathematical relationships that are often assumed to be
universal only hold true under specific norms. This article explores the L1 norm, the L3 norm, as well as their generalization, the Lp norms, their equivalence relationships, and their importance
in finance.
The L1 norm: a measure of absolute deviations
The L1 norm, also known as the norm of absolute deviations, measures the size of a vector by summing the absolute values of its components. Mathematically, for a vector \( x = (x_1, x_2, \dots, x_n) \), the L1 norm is defined as:
Unlike other norms, such as the L2 norm, the L1 norm assigns equal weight to all components, making it a valuable tool for simplifying financial models or imposing constraints.
Consider the vector \( x = (3, -4, 2) \). Its L1 norm is:
\( ||x||_1 = |3| + |-4| + |2| = 3 + 4 + 2 = 9 \)
The L1 norm is often used to promote sparsity in financial portfolios, meaning it limits the number of selected assets. For instance, in optimization models, using the L1 norm helps create
concentrated portfolios with a small number of significant assets.
The L3 norm: sensitivity to large values
The L3 norm places greater emphasis on the larger components of a vector. It is defined as:
\( ||x||_3 = \left( |x_1|^3 + |x_2|^3 + \dots + |x_n|^3 \right)^{1/3} \)
For the same vector \( x = (3, -4, 2) \), the L3 norm is calculated as:
The L3 norm is useful for analyzing phenomena where extreme values play a significant role, such as detecting anomalies in financial time series. Compared to the L1 norm, it amplifies the larger
components more prominently.
Generalization: the Lp norms
The Lp norms form a generalized family for any \( p \geq 1 \). They are defined as:
\( ||x||_p = \left( |x_1|^p + |x_2|^p + \dots + |x_n|^p \right)^{1/p} \)
When \( p = 1 \), we recover the L1 norm. For \( p = 2 \), the norm becomes the Euclidean distance L2. For \( p > 2 \), such as L3, the norm becomes increasingly sensitive to the larger
components. As \( p \to \infty \), the norm converges to the L∞ norm, defined as:
\( ||x||_\infty = \max(|x_1|, |x_2|, \dots, |x_n|) \)
For the vector \( x = (3, -4, 2) \), the L∞ norm is:
The Lp norms are applied in vector spaces1, allowing the evaluation of vector size or relative distance.
Equivalence of norms
In finite dimensions, all Lp norms are equivalent. This means there exist constants \( C_1 > 0 \) and \( C_2 > 0 \) such that, for any vector \( x \):
\( C_1 \cdot ||x||_a \leq ||x||_b \leq C_2 \cdot ||x||_a \)
where \( ||x||_a \) and \( ||x||_b \) represent any two norms. This guarantees that, while the numerical values of Lp norms differ, they describe the relative size of vectors consistently.
For example, consider \( x = (3, -4, 2) \):
Despite the differences, their behavior is consistent, allowing financial analysts to choose the most appropriate norm for their models.
Norms play a crucial role in evaluating risks, optimizing portfolios, and regularizing machine learning models. They are foundational tools that adapt mathematical approaches to the complex needs of modern financial markets.
Écrire commentaire